Most people believe that COPD isn’t just one disease. At the moment, COPD is an umbrella term that includes many different diseases and disease processes. There have also been many papers proposing various subtypes of COPD, but there is no agreement on what the specific subtypes of COPD actually are. Because there isn’t much consensus on how to summarize COPD heterogeneity, current COPD consensus definitions incporpoate COPD heterogeneity in only a limited manner.
The best attempt at synthesis of COPD subtypes is probably the paper by Pinto et al. which found that COPD studies using clustering methods were characterized by “significant heterogeneity in the selection of subjects, statistical methods used and outcomes validated” which made it impossible to compare results across studies or do a meta-analysis of COPD clustering. So, despite lots of attention and effort, progress in COPD subtyping has been slower than expected.
This post addresses two questions. First, “why can’t we agree on COPD subtypes?” Second, “How should we study COPD subtypes so as to produce more reliable results that people could agree on?” At a more general level, the issue is how to apply machine learning to make the best use of the current explosion of data available on large numbers of subjects with COPD. Large studies like COPDGene, SPIROMICS, and others have generated research grade clinical phenotyping, chest CT, and multiple kinds of genomic data that provide a whole new level of resolution into the molecular and lung structural changes that occur in COPD. It’s not unreasonable to think that these data would allow us to reclassify COPD in such a way that patterns of lung involvement combined with molecular signatures of disease processes would allow us to understand and predict the progression of different “flavors” of COPD with much greater accuracy. That is the goal, but getting there has proven more difficult than simply dropping all of these data into a machine learning black box and letting the magic happen.
Most subtyping projects assume that subtypes are distinct groups (as defined by some set of measured characteristics). This seems to make sense. After all, clinicians can easily describe patients with COPD whose clinical characteristics are so different as to suggest that they don’t really have the same disease at all, so why wouldn’t there be distinct groups? However, when we look at data from hundreds or thousands of people with COPD, it is abundantly clear that the distinct patients we can so easily recall don’t represent distinct groups but rather the ends of a continuous spectrum of disease. The image below shows why the COPD subtype concept is poorly suited for clinical reality of COPD.
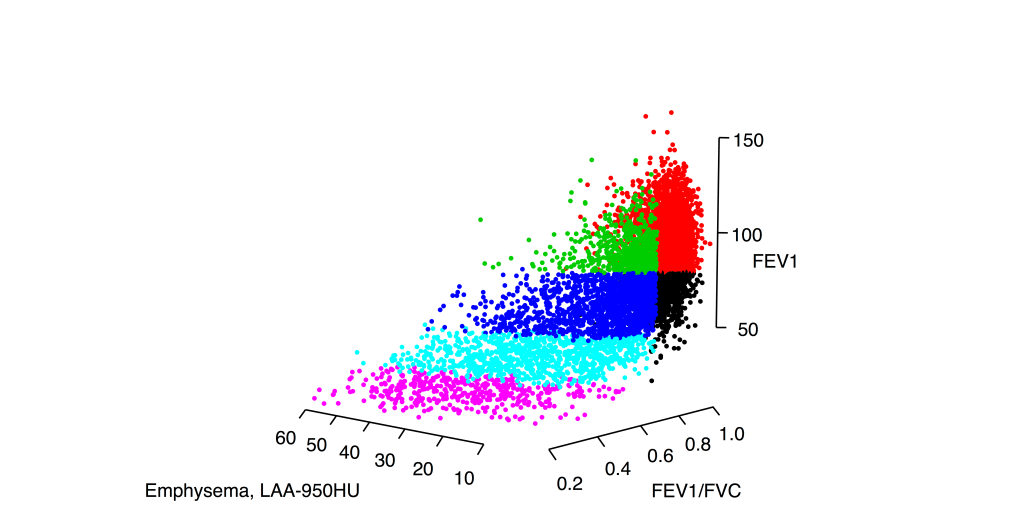
This is the distribution of smokers with and without COPD in a three dimensional space defined by FEV1, FEV1/FVC, and the percentage of emphysema on chest CT scan. Viewing these data in these three dimensions, it is clear that there are no clusters here. If you ask a clustering algorithm to draw partitions in data like this, many algorithms will happily give you clusters despite the fact that there is very little support in the data for distinct groups. Accordingly, these results will be:
- highly sensitive to arbitrary choices of clustering method and parameters
- not reproducible in independent data (as investigated here)
To emphasize this point about low separability, here is the distribution in principal component space for COPDGene subjects colored by their k-means clusters as described in our 2014 paper in Thorax.
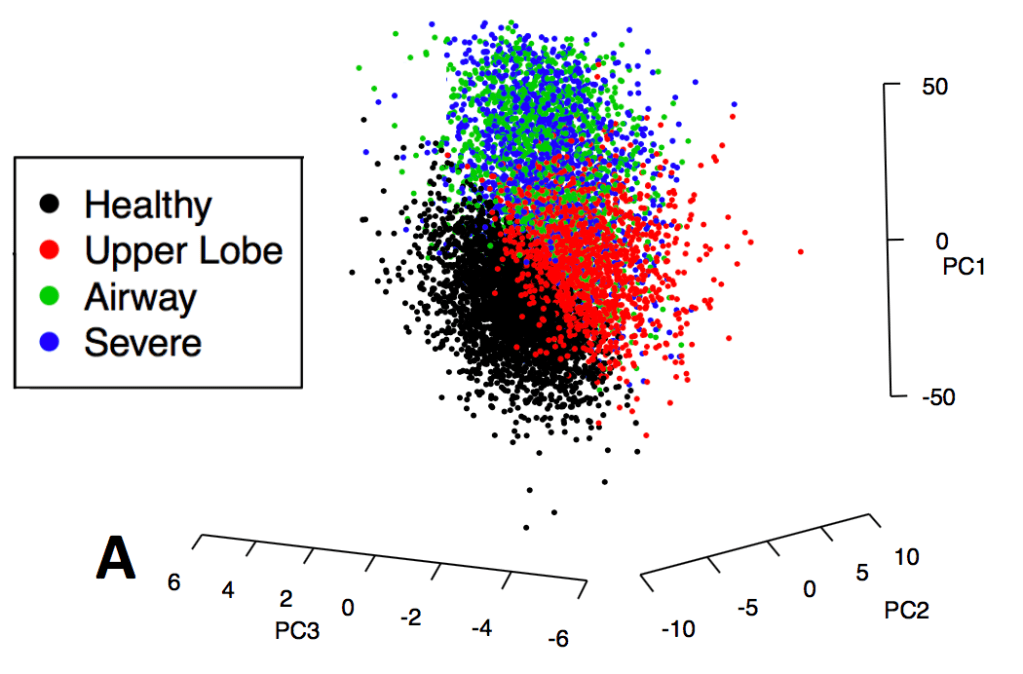
Machine learning involves exploring lots of possible models rather than just a few. So if you’re going to be looking at lots of models, how will you choose a final model in a principled way? In our 2014 clustering paper we used a measure called normalized mutual information that measures the similarity between clustering results performed in the entire dataset compared to smaller subsamples of the data. The figure below shows how the distribution of NMI values across a range of feature sets and number of clusters (k).
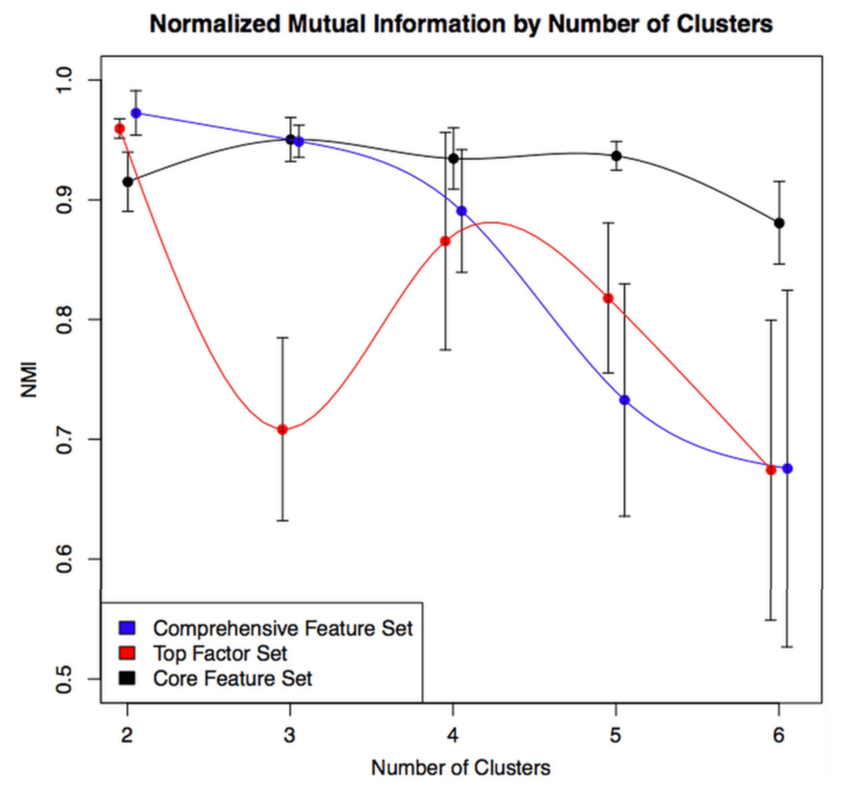
The higher the NMI, the more reproducible the clustering result within our dataset. The variable set with the best internal reproducibility across the widest range of k was the simplest one that consisted of only four variables, but it is also clear that there is no single solution that stands out above the rest. If you want an NMI > 0.9, you have at least six clustering solutions to choose from. And they’re all quite different! The figure below shows how the clustering assignments shift as you go from 3 to 5 clusters.
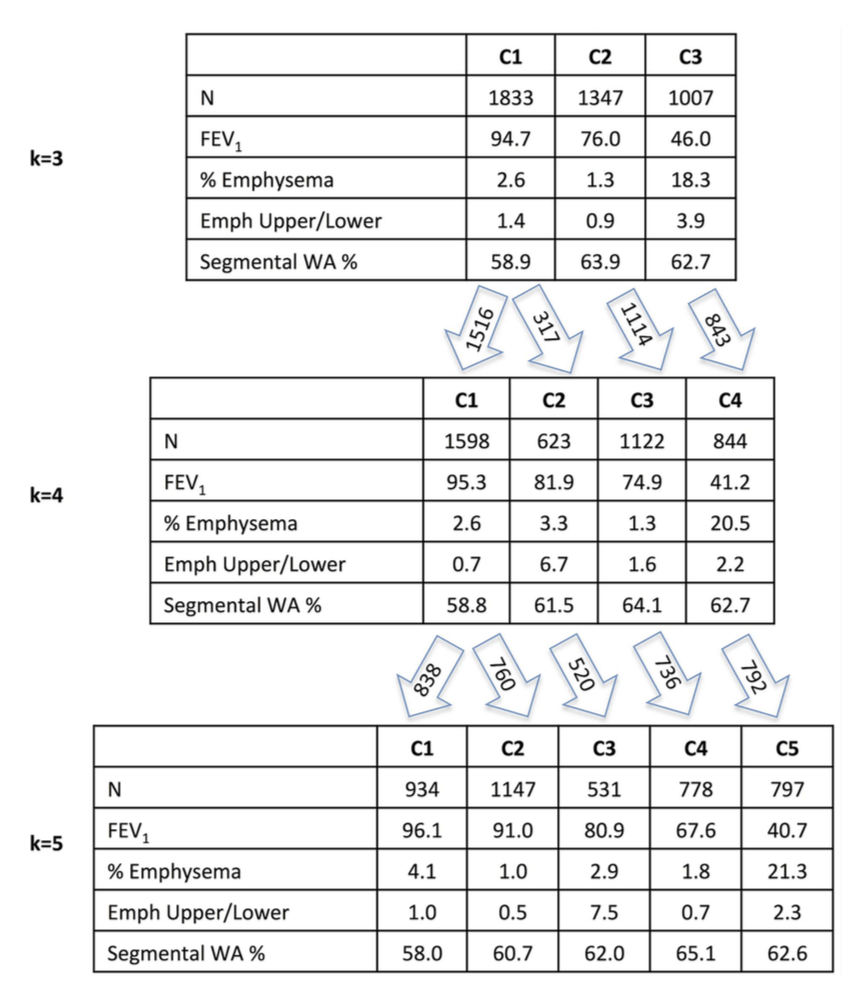
Emph Upper/Lower = emphysema apico-basal distribution
WA% = measure of airway wall thickness
Unfortunately, the choice between 3, 4, or 5 clusters is fairly arbitrary since their NMI values are very similar. So if this paper has been a huge success and transformed COPD care such that every person with COPD was assigned a Castaldi subtype, there are a lot of people who’s COPD subtype would depend on the very arbitrary choice between a final model with 3, 4, or 5 clusters. For example, there are 1,347 people (32%) who are belong to the airway-predominant COPD cluster (high airway wall thickness, low emphysema) in the k=3 solution, but only 778 (19%) in the k=5 solution. So what happened to those other 569 people? They’re bouncing around between subtypes based on fairly arbitrary analysis choices. We certainly don’t want COPD clinical subtypes to be determined based on this sort of arbitrary data analysis choice.
So why do I keep referring to COPD clusters as poorly reproducible despite the fact that the NMI values for our 2014 paper were very high? For three reasons. First, reproducibility subsamples of a single dataset is a lower bar than reproducibility across comparable independent datasets. Second, common sense suggests that algorithmically drawn separations in manifolds are likely to be driven by subtle differences that are dataset specific. Third, a systematic study of cluster reproducibility involving ten COPD cohorts from the US and Europe found only modest reproducibility of COPD clustering results.
So, is clustering useless? No, clustering in COPD is great for data exploration, which can be very enlightening and has demonstrably led to better understanding of COPD heterogeneity and novel molecular discoveries. But for the goal of producing reliable and rational clinical classification, traditional clustering methods are not well-equipped for summarizing COPD heterogeneity in a way that is likely to be highly reproducible. Other approaches are needed for that.

[…] previous posts illustrate that COPD clinical data usually forms a continuum without clusters with the resulting effect that COPD clustering is often poorly reproducible. So why are there still […]
LikeLike
[…] exacerbations or rate of disease progression. In previous posts, the point has been made that the COPD “phenotypic space” is usually a continuum and that continuous “disease axes” provide a more accurate and reproducible […]
LikeLike
[…] Step 5 (The results desert) : We’ve done a lot of things, but we haven’t found a great solution, and we don’t have a good rationale for picking which one of our many clustering results should be the main one (as described in detail in this post). […]
LikeLike
[…] 1: The COPD continuum and the downsides of clustering. Reviews one of our first subtyping papers and discusses the fact that COPD data usually do not have clear clustering structure. […]
LikeLike